FAQ
Audio-/Videodatei publizieren
16: Kognitive Systeme, Vorlesung, SS 2018, 25.06.2018
Autor
Herausgeber
Beteiligtes Institut
Institut für Anthropomatik und Robotik (IAR)
Genre
Beschreibung
- 0:00:00 Starten
- 0:01:37 Vocal Tract Model of Speech
- 0:07:11 Speech Recognition (System Overview)
- 0:10:03 How good is a Recognizer?
- 0:19:01 Dimensions of Difficulty
- 0:27:45 Error Rates vs. Recognition Tasks
- 0:35:13 Die Fundamentalformel der Spracherkennung
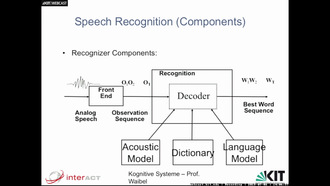
- 0:42:32 Speech Recognition (Components)
- 0:46:36 Voiced and Unvoiced Phonemes
- 0:49:36 Spectrogram
- 0:52:16 Frequency Response of the Basilar Membrane
- 0:54:10 Front End Processing
- 0:56:00 Voiced and Unvoiced Phonemes
- 0:59:48 Speech Recognition (system components)
- 1:00:47 Markov Models
- 1:05:03 Single Fair Coin
- 1:06:11 Discrete Observation HMM
- 1:11:40 Hidden Markov Models
- 1:14:30 Acoustic Modeling
- 1:18:02 HMM Problems and Solutions
- 1:20:54 Evaluation
- 1:24:05 The Forward Algorithm
Laufzeit (hh:mm:ss)
01:27:47
Serie
Kognitive Systeme, Vorlesung, SS 2018
Publiziert am
28.06.2018
Fachgebiet
Lizenz
Aufrufe
103
| Auflösung | 1280 x 720 Pixel |
| Seitenverhältnis | 16:9 |
| Audiobitrate | 128000 bps |
| Audio Kanäle | 2 |
| Audio Codec | aac |
| Audio Abtastrate | 48000 Hz |
| Gesamtbitrate | 934130 bps |
| Farbraum | yuv420p |
| Container | mov,mp4,m4a,3gp,3g2,mj2 |
| Medientyp | video/mp4 |
| Dauer | 5267 s |
| Dateiname | DIVA-2018-500_hd.mp4 |
| Dateigröße | 615.011.238 byte |
| Bildwiederholfrequenz | 25 |
| Videobitrate | 800035 bps |
| Video Codec | h264 |
Embed-Code
Kognitive Systeme, Vorlesung, SS 2018
Folgen 1-21
von 21