FAQ
Audio-/Videodatei publizieren
Grundlagen der automatischen Spracherkennung, WS 2015/2016, gehalten am 30.11.2015, Vorlesung 11
Autor
Beteiligtes Institut
Institut für Anthropomatik und Robotik (IAR)
Genre
Beschreibung
- 0:00:00 Starten
- 0:01:05 Aufgabe
- 0:10:18 Vektorquantisierung
- 0:11:47 Finden von Referenzvektoren
- 0:12:57 K-Mittelwerte
- 0:15:53 Learning VQ
- 0:18:12 LVQ 2, LVQ3
- 0:20:27 LVQ als KNN
- 0:29:42 Literaturempfehlung zu Statische Spracherkennung
- 0:30:39 Stochastik in der Spracherkennung
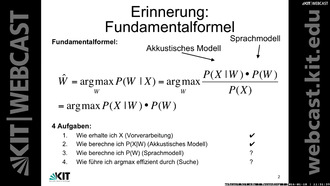
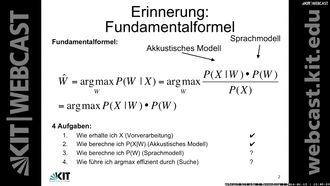
- 0:34:35 Die Fundamentalformel
- 0:39:58 Stochastische ASR - Akustische Modell
- 0:43:56 Stochastischer Prozess
- 0:49:12 Markow-Kette
- 0:51:11 Markow-Kette n-ter Ordnung
- 0:53:01 Markow-Ketten 1.Ordnung
- 0:54:59 Homogene Markow-Ketten 1.Ordnung
- 0:55:46 Beispiele
- 1:02:41 Hidden Markov Models
- 1:10:41 Urne Ball Modell
- 1:12:04 HMM Definition
- 1:15:01 HMM Beobachtungsgenerierung
- 1:16:52 Die HMM Trellis
- 1:18:53 Die Drei Probleme der HMMs
Laufzeit (hh:mm:ss)
01:20:17
Serie
Grundlagen der Automatischen Spracherkennung, WS 2015/2016
Publiziert am
03.12.2015
Fachgebiet
Lizenz
Aufrufe
102
| Auflösung | 1280 x 720 Pixel |
| Seitenverhältnis | 16:9 |
| Audiobitrate | 107080 bps |
| Audio Kanäle | 2 |
| Audio Codec | aac |
| Audio Abtastrate | 48000 Hz |
| Gesamtbitrate | 913083 bps |
| Farbraum | yuv420p |
| Container | mov,mp4,m4a,3gp,3g2,mj2 |
| Medientyp | video/mp4 |
| Dauer | 4817 s |
| Dateiname | DIVA-2015-920_hd.mp4 |
| Dateigröße | 4.096 byte |
| Bildwiederholfrequenz | 25 |
| Videobitrate | 799911 bps |
| Video Codec | h264 |
Mediathek-URL
Embed-Code
Grundlagen der Automatischen Spracherkennung, WS 2015/2016
Folgen 1-22
von 22