FAQ
Audio-/Videodatei publizieren
Grundlagen der automatischen Spracherkennung, WS 2015/2016, gehalten am 13.01.2016, Vorlesung 16
Autor
Beteiligtes Institut
Institut für Anthropomatik und Robotik (IAR)
Genre
Beschreibung
- 0:00:00 Starten
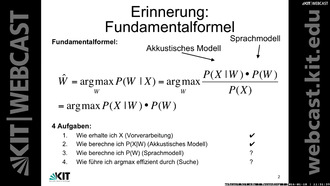
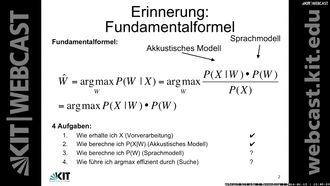
- 0:00:14 Erinnerung: Fundamentalformel
- 0:02:17 Stochastische Sprachmodelle
- 0:03:54 Äquivalenzklassen
- 0:04:36 Schätzen von N-Gramm Wahrscheinlichkeiten
- 0:05:32 Beispiel
- 0:07:05 Bigramme und Trigramme
- 0:10:07 Das Bag-of-Words Experiment
- 0:10:56 Glättung von Sprachmodellparametern
- 0:15:07 Discounting
- 0:17:51 Interpolation (Lineare Glättung)
- 0:23:53 HMM für Interpolationsgewichte
- 0:30:03 Schätzung der Gewichte
- 0:42:03 Deleted Interpolation basierend auf den ""Conditional Counts""
- 0:46:22 Praktische Aspekte
- 0:49:46 Schätzen von y
- 0:52:34 Allgemeines Rahmenwerk für Glättung
- 0:55:17 Weitere Notationen
- 0:59:17 Schätzung von qj und α
- 1:04:24 M bestimmen
- 1:08:06 Good-Turing Discounting
- 1:10:13 Back-Off Sprachmodelle
- 1:13:06 Back-Off LM
- 1:16:53 Katz Backoff
Laufzeit (hh:mm:ss)
01:20:49
Serie
Grundlagen der Automatischen Spracherkennung, WS 2015/2016
Publiziert am
14.01.2016
Fachgebiet
Lizenz
Aufrufe
124
| Auflösung | 1280 x 720 Pixel |
| Seitenverhältnis | 16:9 |
| Audiobitrate | 109859 bps |
| Audio Kanäle | 2 |
| Audio Codec | aac |
| Audio Abtastrate | 48000 Hz |
| Gesamtbitrate | 915858 bps |
| Farbraum | yuv420p |
| Container | mov,mp4,m4a,3gp,3g2,mj2 |
| Medientyp | video/mp4 |
| Dauer | 4849 s |
| Dateiname | DIVA-2016-56_hd.mp4 |
| Dateigröße | 4.096 byte |
| Bildwiederholfrequenz | 25 |
| Videobitrate | 799905 bps |
| Video Codec | h264 |
Mediathek-URL
Embed-Code
Grundlagen der Automatischen Spracherkennung, WS 2015/2016
Folgen 1-22
von 22