Grundlagen der Automatischen Spracherkennung, Vorlesung, WS 2017/18

Autor
Sebastian Stüker, Alexander Waibel
Herausgeber
Genre
Beschreibung
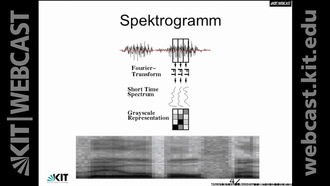
Die Vorlesung erläutert den Aufbau eines modernen Spracherkennungssystems. Der Aufbau wird dabei motiviert ausgehend von der Produktion menschlicher Sprache und ihrer Eigenschaften. Es werden alle Verarbeitungsschritte von der Signalverarbeitung über das Training geeigneter, statistischer Modelle, bis hin zur eigentlichen Erkennung ausführlich behandelt. Dabei stehen statistische Methoden, wie sie in aktuellen Spracherkennungssystemen verwendet werden, im Vordergrund. Somit wird der Stand der Technik in der automatischen Spracherkennung vermittelt. Ferner werden alternative Methoden vorgestellt, aus denen sich die aktuellen entwickelt haben und die zum Teil noch in spezialisierten Fällen in der Spracherkennung zum Einsatz kommen. Anhand von Beispielanwendungen und Beispielen aus aktuellen Projekten wird der Stand der Technik und die Leistungsfähigkeit moderner Systeme veranschaulicht. Zusätzlich zu den grundlegenden Techniken wird auch eine Einführung in die weiterführenden Techniken automatischer Spracherkennung geben, um so zu vermitteln, wie moderne, leistungsfähige Spracherkennungssysteme trainiert und angewendet werden können. Literaturhinweise: * Xuedong Huang, Alex Acero, Hsiao-wuen Hon, Spoken Language Processing, Prentice Hall, NJ, USA, 2001 * Fredrick Jelinek (editor), Statistical Methods for Speech Recognition, The MIT Press,1997, Cambridge, Massachusetts, London, England Weiterführende Literatur * Lawrence Rabiner and Ronald W. Schafer, Digital Processing of Speech Signals, Prentice Hall, 1978 * Schukat-Talamazzini, Automatische Spracherkennung Lehrinhalt: Die Vorlesung erläutert den Aufbau eines modernen Spracherkennungssystems. Der Aufbau wird dabei motiviert ausgehend von der Produktion menschlicher Sprache und ihrer Eigenschaften. Es werden alle Verarbeitungsschritte von der Signalverarbeitung über das Training geeigneter, statistischer Modelle, bis hin zur eigentlichen Erkennung ausführlich behandelt. Dabei stehen statistische Methoden, wie sie in aktuellen Spracherkennungssystemen verwendet werden, im Vordergrund. Somit wird der Stand der Technik in der automatischen Spracherkennung vermittelt. Ferner werden alternative Methoden vorgestellt, aus denen sich die aktuellen entwickelt haben und die zum Teil noch in spezialisierten Fällen in der Spracherkennung zum Einsatz kommen. Anhand von Beispielanwendungen und Beispielen aus aktuellen Projekten wird der Stand der Technik und die Leistungsfähigkeit moderner Systeme veranschaulicht. Zusätzlich zu den grundlegenden Techniken wird auch eine Einführung in die weiterführenden Techniken automatischer Spracherkennung geben, um so zu vermitteln, wie moderne, leistungsfähige Spracherkennungssysteme trainiert und angewendet werden können.
Fachgebiet
Lizenz
Hinweis
Die Beiträge dieser Serie können Sie als Podcast abonnieren.
Embed-Code